Class-agnostic video object segmentation without semantic re-identification
Abstract
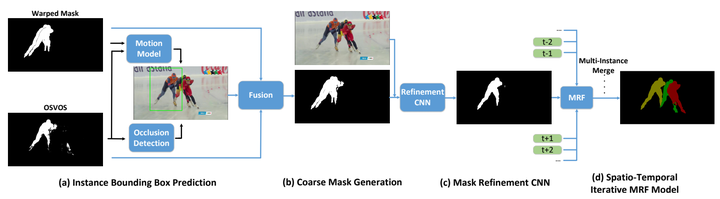
This paper presents a class-agnostic video object segmentation approach that won the 3rd place in the 2018 DAVIS Challenge (semi-supervised track). The proposed approach does not use any semantic object re-identification module and thus is more generic to handle unknown types of objects. Specifically, the approach is composed of four steps: 1) An instance proposal box for a given object is predicted from its history trajectories using a linear motion model with explicit occlusion detection; 2) A coarse mask is generated by fusing the warped mask from the preceding frame and the mask prediction from One-Shot Video Object Segmentation (OSVOS) CNN; 3) The coarse mask, truncated by the instance proposal box, is then fed into a mask refinement CNN to get a more detailed mask; 4) An iterative spatio-temporal refinement is lastly performed to get the final segmentation results. For multiple objects case, each single object is dealt with individually and merged into one mask by considering temporal consistency. The effectiveness of the proposed approach is demonstrated with experiments on very challenging sequences.